Published 08. February 2017
Updated October 2025
Introduction
When migrating your database to Oracle 12+ or a multibyte character set such as AL32UTF8, certain subtle issues may arise that can easily go unnoticed.
Although Oracle’s newer releases simplify many aspects of migration, differences in character storage semantics can still lead to unexpected problems during import or export.
If you don’t prepare for these differences, you may encounter data truncation or skipped records when moving your database.
Fortunately, KeepTool Hora provides an intuitive way to analyze your schema and detect columns that could cause problems before you start the migration.
Character Set Conversion Challenges
In many legacy databases, the character set is single-byte, such as WE8ISO8859P1 or WE8MSWIN1252.
Each character—including special national characters like ä, ö, ü, or ß—is stored as exactly one byte (for example, hexadecimal E4, F6, FC, DF).
However, when migrating to a multibyte character set like AL32UTF8, the same characters may require more than one byte.
As a result, columns that are defined with BYTE semantics might exceed the allowed byte length after conversion.
This means that a column defined as VARCHAR2(4000 BYTE) could now hold fewer characters than before, and data exceeding the limit might cause errors during import.
Guided Analysis in KeepTool
To help you identify such columns, Hora includes a built-in Tools | Find VARCHAR2 columns exceeding multi-byte length command for Character set conversion analysis .
It provides a clear and guided workflow that walks you through the necessary checks step by step.
How to find VARCHAR2 columns exceeding multi-byte length
When you open the dialog, the upper area displays your current session settings for
NLS_LENGTH_SEMANTICS, MAX_STRING_SIZE, and the database character set.
This information is crucial for understanding how Oracle currently interprets column lengths.
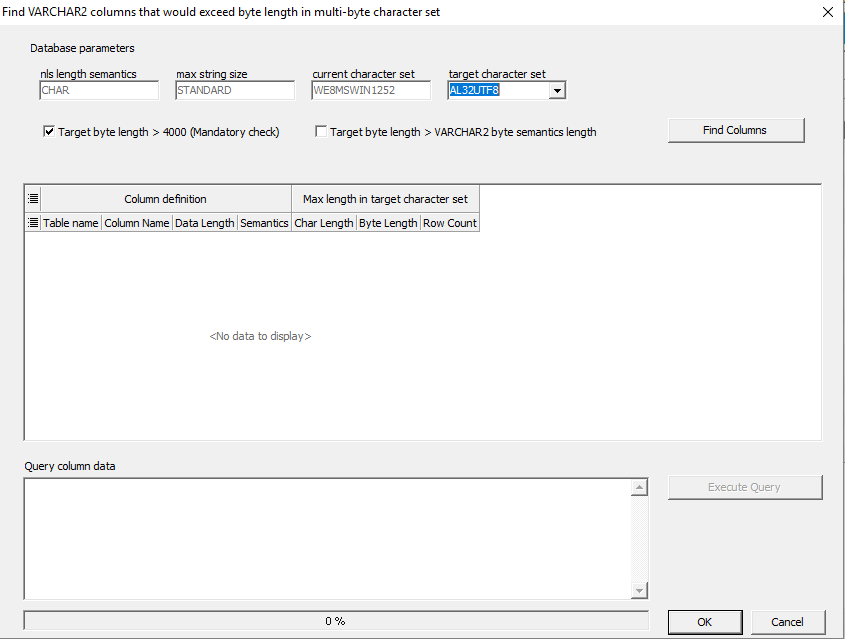
Choosing the target character set to identify character set conflicts
Next, you can select your target character set (for example, AL32UTF8).
Make sure the checkbox “Target byte length > 4000” is selected, and then click Find columns.
Hora will then analyze your schema and list all columns that could exceed the 4000-byte limit after conversion.
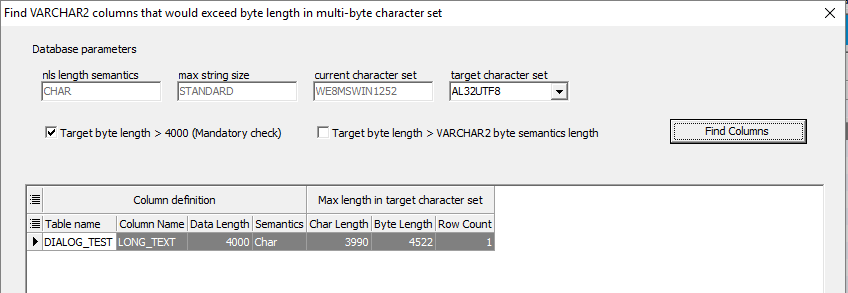
List of columns with possible character set conflicts
The result grid highlights all critical columns.
These are the columns where the actual byte length of the data would become too large once the database is converted to a multibyte character set.
Hora makes it easy to recognize the problem areas at a glance.

Including the optional check
In the memo area below, Hora automatically generates an SQL query that retrieves the affected rows.
This means you can immediately check which specific data entries are responsible for exceeding the limit — without having to build your own analysis query.

Finding conflicted data
Through this guided process, Hora not only detects potential issues but also shows you exactly where and why they occur.
As a result, you can take targeted corrective actions before running your migration export or import.
Taking Corrective Action
Once Hora has identified problematic columns, you can proceed in several ways:
-
Change BYTE semantics to CHAR semantics to measure column length in characters instead of bytes.
-
Trim or adjust data so that no rows exceed the byte limit in the target character set.
-
Migrate large text columns to CLOB if necessary.
By applying these adjustments ahead of time, you ensure that your migration process runs smoothly and without unexpected interruptions.
Summary
Migrating to a multibyte character set like AL32UTF8 can reveal unexpected differences between BYTE and CHAR semantics, particularly when dealing with long text columns.
Without preparation, this can result in data truncation or failed imports.
KeepTool’s Tools | Character set conversion analysis helps you anticipate these issues early.
The dialog guides you through the analysis, highlights all risky columns, and even provides an SQL statement for direct data verification.
Consequently, you can resolve all semantic conflicts before performing the export or import.
➡️ Try KeepTool for free
KeepTool's Oracle tools are designed specifically for developers, DBAs, and support teams.
Based on over 25 years of experience, we continuously optimize our software to make your database analysis and documentation faster, more efficient, and clearer.