Oracle 12c migration experiences some of our customers have been shared with us over the course of the past year 2016. In most cases the customers installed a new pluggable 12c database rather than upgrading the existing database. After that, they transferred data using export and import utilities.
One issue that stood out was how to best deal with the conversion from a single- to a multi-byte character set such as AL32UTF8 that is now the default in Oracle 12c.
In Western countries, many Oracle 11g databases still use single-byte character sets such as WE8ISO8859P1 or WE8MSWIN1252, depending on national language requirements. Here, each character including special national characters such as German letters ä, ö, ü and ß are stored as single-byte values of hexadecimal E4, F6, FC, and DF respectively.
Unicode character sets like AL32UTF8 make it possible to store a variety of national characters from different languages as well as thousands of ideographic symbols used by Asian languages. The drawback is that a single character may require more than one byte.
When creating a table structure, you can define VARCHAR2 column lengths using either BYTE or CHAR length semantics. While working with single-byte characters, you do not need to be concerned with the difference. When preparing for an Oracle 12c migration including AL32UTF8 character set conversion, it is advisable to first make sure the data will fit the target storage allocation.
As a first step, you may want to alter columns of the decommissioned database to character semantics, and possibly change the database parameter NLS_LENGTH_SEMANTICS as well. This will ensure that the target structure can store the appropriate number of characters regardless of the length in bytes.
Unfortunately, that is not the whole story. Regardless of the NLS_LENGTH_SEMANTICS setting, the overall length for VARCHAR2 columns is limited to 4,000 bytes. However, in Oracle 12c, it is possible to extend the maximum length up to 32,767 bytes by changing the initialization parameter MAX_STRING_SIZE to EXTENDED, although that option does not figure into the following example.
Keeping in mind that those special characters like ä, ö, ü and ß are now stored as 2 bytes, it is possible that data stored in a VARCHAR2 (4000) column may exceed the maximum byte length of the target structure. The only way to avoid those records from being skipped by the import utility is to find and trim existing data before export.
That is where our new dialog comes in. To illustrate how the new Hora utility helps you identify such data, suppose we have
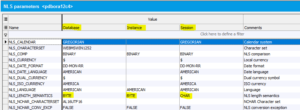
You can check these settings on Hora’s database page on the NLS settings tab.
Furthermore, let’s suppose there is a table DIALOG_TEST with the following columns:
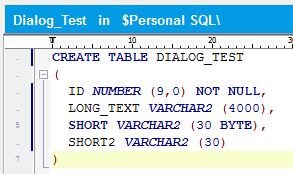
The column SHORT2 uses NLS_LENGTH_SEMANTICS, according to the session parameter, which is CHAR.
We will populate this table as follows:

The long string in the first row (ID=1) consists of 133 occurrences of the string ‘abcdefghijklmnopqrstuvwxyzäöüß,’ which is 30 characters as well as 30 bytes in length. We thus end up with a field containing 133*30 = 3990 characters as well as bytes. If the content of the table is exp/imported to an AL32UTF8 database, we end up with a required amount of 133*(30+4) = 4,522 bytes that does not fit the standard maximum of 4,000 bytes.
The strings in SHORT and SHORT2 are each 30 characters in length. In an AL32UTF8 database, you need to use CHAR semantics, because the length in bytes is greater than 30.
The new dialog is made available from Hora’s “Schema” main menu item.
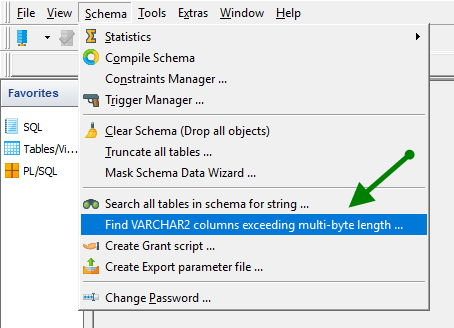
The header section of the dialog shows
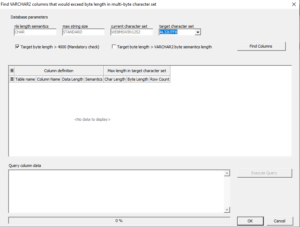
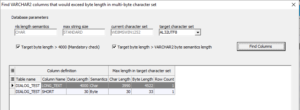
The first checkbox “Target byte length > 4000” is always checked. After the “Find Columns” button is pressed, the data grid is populated with all table columns having data that does not fit within the upper limit of 4,000 bytes of the target character set.
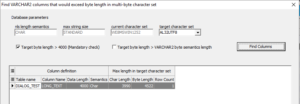
In this example, the column LONG_TEXT has been found, because the longest value requires 4,522 bytes in the multi-byte character set. To accommodate this row, you can either truncate the data before the conversion, or change the target database parameter MAX_STRING_SIZE to EXTENDED.
When both boxes are checked, the dialog makes an additional check to find columns where the byte length in the target character set would exceed the number of bytes according to the column definition based on BYTE semantics. The column SHORT is shown as impacted, while SHORT2 is not. SHORT has been defined as 30 bytes in length. In AL32UTF8, it would require 33 bytes because of the three superscripted characters at the beginning of the string ‘ÄÖÜ456789012345678901234567890.’ SHORT2 is not shown as impacted because it has been defined as 30 characters as a result of the current NLS_LENGTH_SEMANTICS database setting.
The memo box in the lower portion of the dialog shows a SQL query. When executed, it shows the data causing length violations for the currently selected table column—in this example, DIALOG_TEST.LONG_TEXT.
The results appear in the SQL results window.
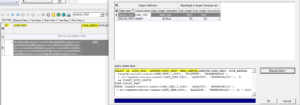
To sum it up, the new dialog speeds up the process of identifying table columns and data that may cause problems when converting to a multi-byte character set, for example in the context of Oracle 12c migration.
Explore possibilities of KeepTool.
