Oracle 12c Umstellung ist ein viel diskutiertes Thema, wovon uns einige unserer Kunden im Laufe des vergangenen Jahres von ihren Erfahrungen berichtet haben. In vielen Fällen wurde dabei kein direkter Upgrade der bestehenden Datenbank vorgenommen. Vielmehr wurde eine neue „pluggable“ 12c Datenbank eingerichtet. Anschließend wurden die Daten über die Export/Import-Werkzeuge migriert.
Ein in diesem Zusammenhang häufig genanntes Thema war die Frage, wie man möglichst fehlerfrei zu einem Multibyte-Zeichensatz wie AL32UTF8 (Voreinstellung bei Oracle 12c Umstellung) wechselt.
Vor allem in den westlichen Ländern werden in Oracle 11g-Datenbanken häufig noch sprachenabhängig 1-Byte-Zeichensätze wie WE8ISO8859P1 oder WE8MSWIN1252 benutzt. Hier wird jedes Zeichen, also auch länderspezifische Symbole wie die deutschen Umlaute ä, ö, ü und ß, in einem einzelnen Byte abgelegt, z.B. hexadezimal E4, F6, FC und DF.
Unicode-Zeichensätze wie AL32UTF8 sind in der Lage, eine Vielzahl von länderspezifischen Zeichen aus unterschiedlicher Sprachen einschließlich ideographischer Symbole abzubilden, wie sie in asiatischen Sprachen verwendet werden. Dieser Vorteil wird allerdings dadurch erkauft, dass für ein Zeichen ggf. mehr als ein Byte erforderlich wird.
Beim Aufbau einer Tabellenstruktur können Sie die Länge von VARCHAR2-Spalten entweder als Anzahl Bytes oder als Anzahl Zeichen definieren. Solange Sie mit einem Zeichensatz von einem Byte Länge arbeiten, brauchen Sie sich nicht um den Unterschied zwischen BYTE und CHAR –Semantik zu kümmern. Wenn Sie nun den Umstieg auf Oracle 12c mit einhergehender Zeichensatzkonvertierung zu AL32UTF8 vorbereiten, ist es empfehlenswert vorher sicherzustellen, dass alle Daten ins Zielsystem passen.
Im ersten Schritt kann man noch im abgelösten System die Spalten per ALTER TABLE in CHAR-Semantics überführen, und ggf. auch den Datenbankparameter NLS_LENGTH_SEMANTICS mit ändern. Damit ist sichergestellt, dass später die Ziel-Struktur dieselbe Anzahl Zeichen aufnehmen kann, und zwar unabhängig von der tatsächlichen Anzahl Bytes.
Leider reicht das noch nicht aus. Unabhängig von der gewählten NLS_LENGTH_SEMANTICS-Einstellung darf die Länge von VARCHAR2-Spalten die Grenze von 4.000 Bytes nicht überschreiten. In Oracle 12c ist es zwar möglich, die maximale Länge auf bis zum 32.767 Bytes durch entsprechendes Setzen des Initialisierungsparameters MAX_STRING_SIZE auf EXTENDED zu erhöhen, was wir im Rahmen dieses Beispiels aber nicht tun wollen.
Da Sonderzeichen wie ä, ö, ü und ß nun zwei Bytes belegen, kann es also beispielsweise dazu kommen, dass nicht mehr alle Daten aus einer VARCHAR2(4000)-Spalte in die Zielstruktur passen. Da hilft nur, die Daten ausfindig zu machen und bereits vor dem Export zu kürzen, ansonsten werden die betroffenen Zeilen beim Import übergangen und eine entsprechende Fehlermeldung ausgegeben.
Nun kommen wir dazu zu zeigen, was unser neuer Dialog leistet. Um zu zeigen, wie Hora sie beim Auffinden der entsprechenden Daten unterstützt, nehmen wir an,
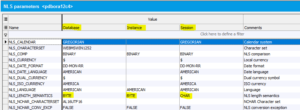
Sie können diese Einstellungen in Hora auf der Database-Seite, Lasche NLS parameters überprüfen.
Nehmen wir weiter an, dass es in der Ausgangs-Datenbank eine Tabelle DIALOG_TEST mit folgenden Spalten gibt:
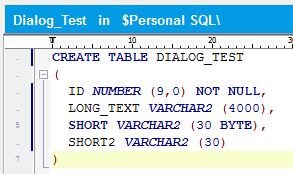
Die Spalte SHORT2 benutzt nls_length_semantics entsprechend des gesetzten Session-Parameters, d.h. CHAR.
Wir füllen die Tabelle mit den hier gezeigten Werten:

Die lange Zeichenkette in der ersten Zeile (ID=1) enthält 133 mal den String ‘abcdefghijklmnopqrstuvwxyzäöüß’, der eine Länge von 30 Zeichen bzw. 30 Bytes hat. Daraus ergibt sich eine gesamte Feldlänge von 133*30 = 3.990 Zeichen bzw. Bytes. Wenn der Inhalt der Tabelle in eine AL32UTF8-Datenbank exp/importiert wird, erhöht sich der Speicherbedarf auf 133*(30+4) = 4.522 Bytes, womit das Standard-Maximum von 4.000 Bytes überschritten wird.
Die Zeichenketten in SHORT und SHORT2 sind jeweils 30 Zeichen lang. In einer AL32UTF8-Datenbank müssen diese CHAR semantics benutzen, damit alle 30 Zeichen hinein passen.
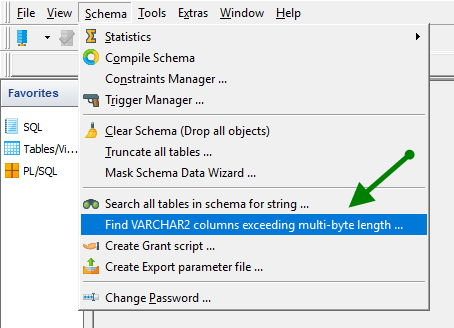
Der neue Dialog kann von Horas“Schema”-Menü aufgerufen werden:
Der Kopfbereich des Dialogs zeigt
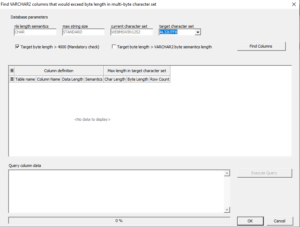
Das erste Kontrollkästchen “ Target byte length > 4000“ ist immer angekreuzt. Nachdem der Schalter „Find columns“ geklickt wurde, zeigt die Tabellendarstellung darunter alle Tabellenspalten an, deren Daten im Ziel-Zeichensatz die Byte-Länge von 4.000 Zeichen überschreiten.
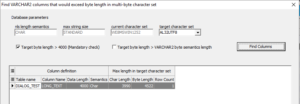
Im Beispiel wurde die Spalte LONG_TEXT gefunden. Der längste Wert im Multi-Byte-Zeichensatz 4.522 Bytes erfordern würde. Sie können das Problem lösen, indem Sie entweder die Daten vor der Konvertierung beschneiden oder den Datenbankparameter MAX_STRING_SIZE auf EXTENDED ändern.
Wenn beide Kontrollkästchen ausgewählt sind, führt der Dialog eine zusätzliche Überprüfung durch, um Spalten zu finden, deren Byte-Länge in der Zieldatenbank die Anzahl von Bytes bezogen auf die Spaltendefinition basierend auf der BYTE-Semantik überschreiten würde. Die Spalte SHORT wird als betroffen angezeigt, während SHORT2 nicht gemeldet wird. SHORT war mit 30 Byte Länge definiert. In AL32UTF8 würde es aber 33 Bytes benötigen wegen der drei Umlaute am Anfang der Zeichenkette ‘ÄÖÜ456789012345678901234567890‘. SHORT2 wird nicht als betroffen angezeigt, weil es als Ergebnis der aktuellen Datenbankeinstellung NLS_LENGTH_SEMANTICS bereits als 30 Zeichen definiert war.
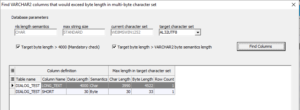
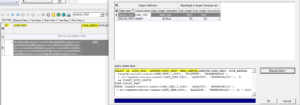
Das Memofeld im unteren Teil des Dialogs zeigt eine SQL-Abfrage. Wird diese ausgeführt, werden die Daten angezeigt, die zu einer Verletzung der Längenüberprüfung der Bezugsspalte führen, in diesem Fall DIALOG_TEST.LONG_TEXT . Das Ergebnis der Abfrage erscheint im SQL-Ergebnisfenster:
Zusammengefasst gesagt, erspart Ihnen der neue Dialog viel Zeit, um Spalten und deren Daten zu identifizieren, die Probleme beim Umstieg in einen Mehrbyte-Zeichensatz, z.B. bei Oracle 12c Umstellung verursachen können.
Entdecken Sie die Möglichkeiten von KeepTool.
